This paper proposed a CNN framework for object instance segmentation. The method is called Mask R-CNN, which is the extension of faster R-CNN by adding an FCN branch for predicting segmentation masks on each RoI.
Autoencoder is a simple 3-layer neural network where output units are directly connected back to input units. E.g. in a network like this: output[i] has edge back to input[j] for every hidden node. Usually, the number of hidden units is much less than the number of visible ones. As a result, when you pass data through such a network, it first encodes input vector to fit a smaller representation and then decodes it back. The task of the training is to minimize an error of reconstruction or find the most efficient compact representation for input data. The AEs (Autoencoders) are similar to PCA and can be used to dimension reduction. The hidden layer decoded features can be used as input features for downstream classification or another AE. RBM is a generative artificial neural network that can learn a probability distribution over a set of inputs. RBMs are a variant of Boltzmann machines , with the restriction that...
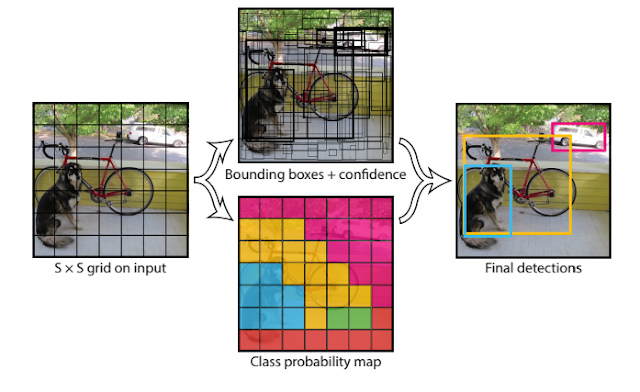
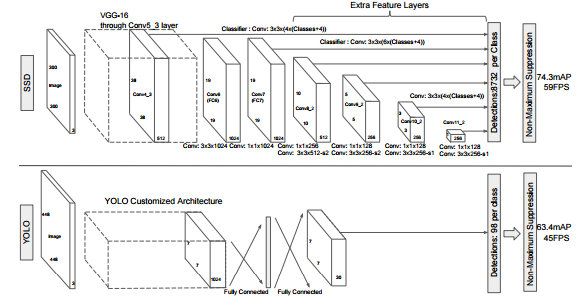
Title: You Only Look Once: Unified, Real-Time Object Detection YOLO is a new approach for object detection. You only need run a single CNN on the image once and make the decision for each grid. Instead of using the sliding windows or region proposes. the YOLO proposed to divide the image to S*S grid and predict each grid with regression. Contribution: The traditional model will do a classification for each proposal or sliding window, but the proposed YOLO divide the image to S*S grid and train a regression model. The ground truth target vector has the dimension of S*S*(B*5+C). Each grid cell predicts B bounding boxes and confidence scores for those boxes. The confidence score reflects how confidence the current grid contain the object and also how accurate it thinks the box is that it predicts. Network: The network has 24 constitutional layers followed by 2 fully connected layers. There are four 2*2 max-pooling layers with stride 2. Instead of inception modules used by ...
SSD is the extension or updating version of YOLO. Compared with YOLO: 1 SSD use the multi-scale feature maps for detection, but the YOLO only use one scale for detection. 2 Before the decision layer, the YOLO use the fully connected layer for detection, but the SSD use the convolution filter for detection, which can improve the final detection performance. 3 Default boxes and aspect ratios. there are a set of default bounding boxes with each feature map cell for multiple feature maps at the top of the network. R-CNN: Selective Search Region Proposals; SVM classification Fast R-CNN: Selective Search Region Proposals; Shared computation by using SSP. Faster R-CNN: Region Proposal Network OverFeat VS SSD: If the SSD only use one default box per location from the topmost feature map, the SSD would have similar architecture to OverFeat. YOLO VS SSD: If use the whole topmost feature map and add a fully-connected layer for predictions instead of convolutional predictors, it...



Comments
Post a Comment