You Only Look Once
Title: You Only Look Once: Unified, Real-Time Object Detection
YOLO is a new approach for object detection. You only need run a single CNN on the image once and make the decision for each grid. Instead of using the sliding windows or region proposes. the YOLO proposed to divide the image to S*S grid and predict each grid with regression.
Contribution:
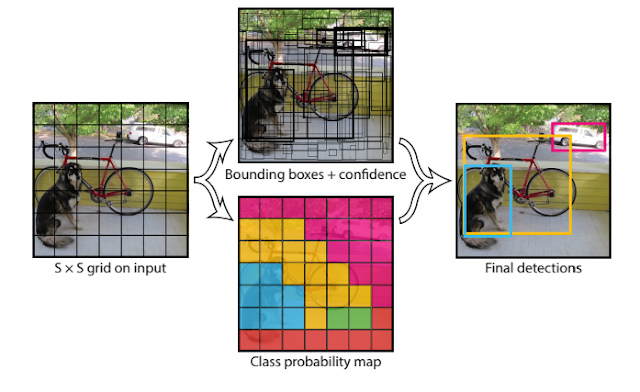 The traditional model will do a classification for each proposal or sliding window, but the proposed YOLO divide the image to S*S grid and train a regression model. The ground truth target vector has the dimension of S*S*(B*5+C). Each grid cell predicts B bounding boxes and confidence scores for those boxes. The confidence score reflects how confidence the current grid contain the object and also how accurate it thinks the box is that it predicts.
The traditional model will do a classification for each proposal or sliding window, but the proposed YOLO divide the image to S*S grid and train a regression model. The ground truth target vector has the dimension of S*S*(B*5+C). Each grid cell predicts B bounding boxes and confidence scores for those boxes. The confidence score reflects how confidence the current grid contain the object and also how accurate it thinks the box is that it predicts.
Network:
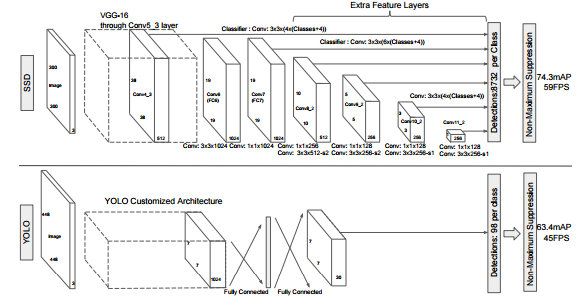
 The network has 24 constitutional layers followed by 2 fully connected layers. There are four 2*2 max-pooling layers with stride 2. Instead of inception modules used by GoogLeNet, the YOLO simply use 1*1 reduction layers followed by 3*3 convolutional layers.
The network has 24 constitutional layers followed by 2 fully connected layers. There are four 2*2 max-pooling layers with stride 2. Instead of inception modules used by GoogLeNet, the YOLO simply use 1*1 reduction layers followed by 3*3 convolutional layers.
VS DPM:
DPM use sliding windows, which can be very slow. DPM[10] use a disjoint pipeline. They first use the CNN to learn and extract features and then use the SVM to do the classification.
VS R-CNN: Use the region proposals, which is faster than DMP but still very slow. And they still use a disjoint pipeline. The testing time for each image is 40 seconds.
VS fast and faster R-CNN:
Fast R-CNN speeds up the R-CNN by sharing computation. And the faster R-CNN focused on speeding up the R-CNN by using a neural network to generate the proposals region instead of selective search.
VS Deep MultiBox:
MultiBox can not perform general object detection and is still just a piece in a larger detection pipeline.
VS OverFeat:
OverFeat efficiently performs sliding window detection but it is still a disjoint system.
VS MultiGrasp:
MultiGrasp only needs to predict a single region for an image containing one object. It doesn't have to estimate the size, location, or boundaries of the object. YOLO can predict both the bounding boxes and class probabilities for multiple objects of multiple classes in one image.
The strength:
1 The YOLO can simultaneously predict multiple bounding boxes and class probabilities for those boxes, instead of doing the classification for each sliding windows or region proposals.
2 Extremely fast, the 24 convolutional layers YOLO network can run at 45 frames per second, and the 9 convolutional layers fast YOLO network can run at 150 fps.
3 Since it can see the entire image during training and test time, so it can encode contextual background information about classes. YOLO make less than half the number of background errors compared to fast R-CNN.
The weak:
While the speed of YOLO is pretty fast and sacrifice the accuracy, so YOLO struggles to precisely localize some object, especially small ones.
The loss is a Smooth L1 loss, which is a segmentation loss function. When the absolution value is less 1, it'a the L2 Euclidean distance, otherwise is L1 loss.
YOLO is a new approach for object detection. You only need run a single CNN on the image once and make the decision for each grid. Instead of using the sliding windows or region proposes. the YOLO proposed to divide the image to S*S grid and predict each grid with regression.
Contribution:

Network:

VS DPM:
DPM use sliding windows, which can be very slow. DPM[10] use a disjoint pipeline. They first use the CNN to learn and extract features and then use the SVM to do the classification.
VS R-CNN: Use the region proposals, which is faster than DMP but still very slow. And they still use a disjoint pipeline. The testing time for each image is 40 seconds.
VS fast and faster R-CNN:
Fast R-CNN speeds up the R-CNN by sharing computation. And the faster R-CNN focused on speeding up the R-CNN by using a neural network to generate the proposals region instead of selective search.
VS Deep MultiBox:
MultiBox can not perform general object detection and is still just a piece in a larger detection pipeline.
VS OverFeat:
OverFeat efficiently performs sliding window detection but it is still a disjoint system.
VS MultiGrasp:
MultiGrasp only needs to predict a single region for an image containing one object. It doesn't have to estimate the size, location, or boundaries of the object. YOLO can predict both the bounding boxes and class probabilities for multiple objects of multiple classes in one image.
The strength:
1 The YOLO can simultaneously predict multiple bounding boxes and class probabilities for those boxes, instead of doing the classification for each sliding windows or region proposals.
2 Extremely fast, the 24 convolutional layers YOLO network can run at 45 frames per second, and the 9 convolutional layers fast YOLO network can run at 150 fps.
3 Since it can see the entire image during training and test time, so it can encode contextual background information about classes. YOLO make less than half the number of background errors compared to fast R-CNN.
The weak:
While the speed of YOLO is pretty fast and sacrifice the accuracy, so YOLO struggles to precisely localize some object, especially small ones.
The loss is a Smooth L1 loss, which is a segmentation loss function. When the absolution value is less 1, it'a the L2 Euclidean distance, otherwise is L1 loss.

Comments
Post a Comment